6. Working with spreadsheets#
 Load tutorial into dapta app.
Load tutorial into dapta app.
 View files on Github.
View files on Github.
Duration: 15 min
In this example we explore the use of spreadsheets and macros within simulation workflows.
We replicate the Simple optimisation problem simulation workflow, but this time using the spreadsheet component libreoffice-comp for the paraboloid function calculation instead of a pure python component.
Don’t have time to work though the example yourself? Watch the video tutorial instead.
6.1. Component description#
Spreadsheets, such as Microsoft’s Excel® files, are widely used in engineering.
In simulation workflows, spreadsheets can be used to:
import data, from experiments for example;
perform calculations on input data in an automated fashion;
record, visualise and store outputs.
Using the libreoffice-comp component API, spreadsheets can easily be integrated into any dapta Run.
The libreoffice-comp includes a full installation of LibreOffice, which includes a spreadsheet editor (Calc).
Calc can open and save files in its native Open Document Format (.ods), as well as Microsoft Excel® format (.xls), and it is also is compatible with macros (currently supported languages are LibreOffice Basic, BeanShell, JavaScript, and Python, with some support for importing Microsoft VBA macros too).
To find out more about writing LibreOffice macros, we recommend having a look at the Getting Started with Macros guide. Reference 1 also provides a good introduction to python macros for Calc.
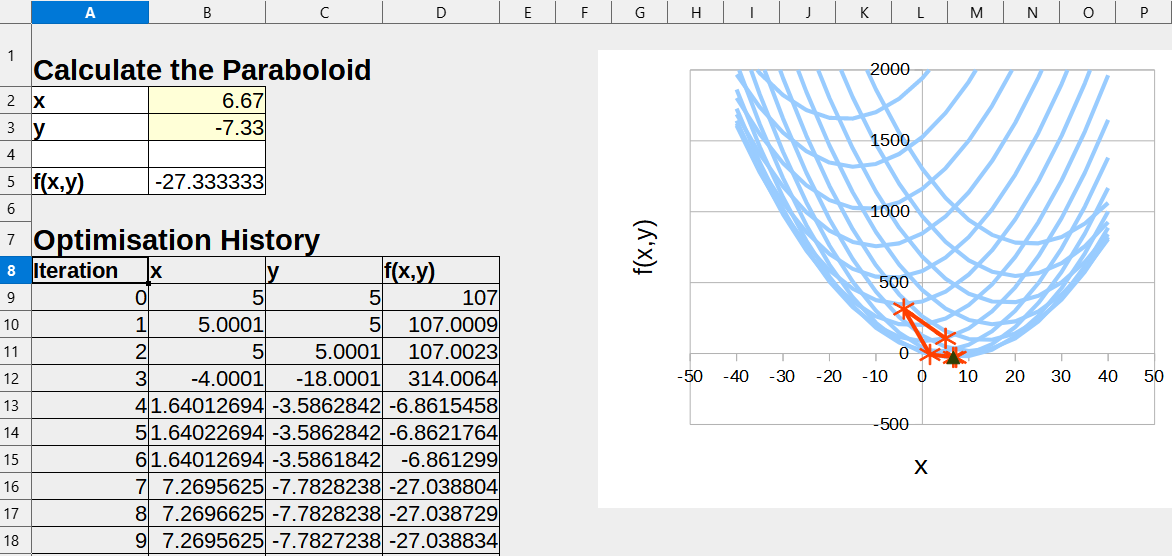
Download the example spreadsheet (shown in the figure above) here: paraboloid.ods.
It includes a VBA macro that automatically calculates the paraboloid function f(x,y) from the Simple component analysis example, whenever the spreadsheet x and y inputs are updated. The spreadsheet also contains an initially empty optimisation history table, which will be used to store and plot the optimisation history data during the Run.
6.2. Opening a saved session#
Since we already created and analysed the paraboloid component previously, we can load our previous session to speed things up.
Select Open from the interface controls to load the JSON formatted version of our previous session (dapta_input.json).
Alternatively, copy the object below into a text editor and save it locally, then select Open to load it.
{
"components": [
{
"name": "paraboloid",
"api": "generic-python3-comp:latest",
"options": {},
"parameters": {
"user_input_files": [],
"x": 5.0,
"y": 5.0,
"f_xy": 0.0
},
"inputs": {
"x": "default",
"y": "default"
},
"outputs": {
"f_xy": "default"
}
}
],
"connections": [],
"workflow": {
"start": "paraboloid",
"end": "paraboloid"
}
}
The paraboloid component should have appeared in the workspace, but the question mark next to the component name indicates that it is missing some data.
6.3. Update the paraboloid component#
Copy the contents of the new setup.py and compute.py API files below into a text editor and save the files locally:
The
setup.pyfunction is similar to the previous one, but it also copies the spreadsheet file into the outputs folder and starts LibreOffice in headless mode by calling thestart_libreofficefunction.The
compute.pyfunction opens the spreadsheet, writes the input x and y values to the input cells (which automatically executes the spreadsheet macro), and then copies the current x, y and calculated f(x,y) values to the optimisation history table. This also automatically updates the line plots. Finally the spreadsheet is saved and closed.
Open the paraboloid component by selecting it in the workspace.
Update the Properties tab:
From the API dropdown menu, choose
libreoffice-comp:latestUpload the new
setup.pyandcompute.pyAPI files by clicking on the corresponding links
Then, update the Parameters tab:
Add the following key / value pair to the JSON object:
"ods_file": "paraboloid.ods"Upload the input spreadsheet (paraboloid.ods) by selecting
upload user input files.
Save and close the component by selecting the Save data button.
You can check that the component works as expected by executing the Run now, or you can add a driver component in the next section before launching the Run.
from datetime import datetime
from pathlib import Path
from shutil import copy2
from libreoffice import start_libreoffice
def setup(
inputs: dict = {"design": {}, "implicit": {}, "setup": {}},
outputs: dict = {"design": {}, "implicit": {}, "setup": {}},
parameters: dict = {
"user_input_files": [],
"inputs_folder_path": "",
"outputs_folder_path": "",
},
) -> dict:
"""A user editable setup function."""
# start libreoffice in headless mode
start_libreoffice()
# check that the spreadsheet file has been uploaded
inputs_folder = Path(parameters["inputs_folder_path"])
if not (inputs_folder / parameters["ods_file"]).is_file():
raise FileNotFoundError(
f"{parameters['ods_file']} needs to be uploaded by the user."
)
# copy spreadsheet to output folder
run_folder = Path(parameters["outputs_folder_path"])
copy2(
inputs_folder / parameters["ods_file"],
run_folder / parameters["ods_file"],
)
# set default inputs
if inputs:
for input_key, input_value in inputs["design"].items():
if input_value == "default":
try:
inputs["design"][input_key] = float(parameters[input_key])
except Exception as e:
print(f"Could not find {input_key} in the input parameters.")
# initialise outputs - required for OpenMDAO
if outputs:
for output_key, output_value in outputs["design"].items():
if output_value == "default":
try:
outputs["design"][output_key] = float(parameters[output_key])
except Exception as e:
print(f"Could not find {output_key} in the input parameters.")
message = f"{datetime.now().strftime('%Y%m%d-%H%M%S')}: Setup completed."
print(message)
return {
"message": message,
"parameters": parameters,
"inputs": inputs,
"outputs": outputs,
}
from datetime import datetime
from pathlib import Path
from libreoffice import store, open_file
def compute(
inputs: dict = {"design": {}, "implicit": {}, "setup": {}},
outputs: dict = {"design": {}, "implicit": {}, "setup": {}},
partials: dict = {},
options: dict = {},
parameters: dict = {
"user_input_files": [],
"inputs_folder_path": "",
"outputs_folder_path": "",
},
) -> dict:
"""A user editable compute function."""
run_folder = Path(parameters["outputs_folder_path"])
print("Starting user function evaluation.")
# open saved spreadsheet
file = str(run_folder.resolve() / parameters["ods_file"])
model = open_file(path=file)
# add data and plot
model, f_xy = paraboloid(model, inputs["design"])
outputs["design"]["f_xy"] = f_xy
# save spreadsheet
store(model, file=file)
model.close(True)
message = f"{datetime.now().strftime('%Y%m%d-%H%M%S')}: Saved ODS spreadsheet."
print(message)
return {"message": message, "outputs": outputs}
def paraboloid(model, inputs):
# set inputs in spreadsheet
sheet = model.Sheets.getByIndex(0)
sheet.getCellRangeByName("B2").Value = inputs["x"]
sheet.getCellRangeByName("B3").Value = inputs["y"]
# get calculated value
f_xy = sheet.getCellRangeByName("B5").Value
# store inputs and outputs in the Optimisation History ranges
starting_row = 8
row = starting_row
while True:
if "EMPTY" in str(sheet[row, 0].getType()):
break
else:
row += 1
# set current iteration number
if row == starting_row:
sheet[row, 0].Value = 0
else:
sheet[row, 0].Value = sheet[row - 1, 0].Value + 1
# set x, y, f_xy
sheet[row, 1].Value = inputs["x"]
sheet[row, 2].Value = inputs["y"]
sheet[row, 3].Value = f_xy
return model, f_xy
6.4. Adding the driver component#
We will re-use the OpenMDAO driver we used previously in the Simple optimisation problem. We adjust the driver parameters for this optimisation problem:
The calculation of total derivatives across the chained components (using finite differencing) is requested by setting
"approx_totals": trueand"fd_step": 0.0001in the driver parameters.Optimisation iteration history plots are requested by adding the “plot_history” option into the “visualise” parameter list.
To create the driver component:
Right-click in the workspace and select
Add Empty Node. Select the empty component to edit it.In the
Propertiestab, fill in the component name,open-mdao, and select the component APIgeneric-python3-driver:latest.Copy the contents of the
setup.py,compute.py,requirements.txtfiles from below into a text editor, save them locally. Then upload them under thePropertiestab.In the
Propertiestab check the box next to theDriveroption.Copy the contents of the parameters JSON object below into the
Parameterstab text box.Copy the contents of the
om_component.pyfile from below into a text editor and save it locally. Then upload it under theParameterstab by selectingupload user input files.Select
Save datato save and close the component.
from datetime import datetime
from pathlib import Path
def setup(
inputs: dict = {"design": {}, "implicit": {}, "setup": {}},
outputs: dict = {"design": {}, "implicit": {}, "setup": {}},
parameters: dict = {
"user_input_files": [],
"inputs_folder_path": "",
"outputs_folder_path": "",
},
) -> dict:
"""Editable setup function."""
if "driver" not in parameters:
# assume we want to run an optimisation with default settings
parameters["driver"] = {"type": "optimisation"}
message = f"{datetime.now().strftime('%Y%m%d-%H%M%S')}: Setup completed."
return {"message": message, "parameters": parameters}
from datetime import datetime
from pathlib import Path
import traceback
from contextlib import redirect_stdout
import numpy as np
import json
from copy import deepcopy
from concurrent.futures import ThreadPoolExecutor
import openmdao.api as om
from matplotlib import pyplot as plt # type: ignore
from om_component import OMexplicitComp, OMimplicitComp # type: ignore
OPENMDAO_REPORTS = None
OM_DEFAULTS = {
"nonlinear_solver": {
"class": om.NewtonSolver,
"kwargs": {"solve_subsystems": False},
},
"linear_solver": {
"class": om.DirectSolver,
"kwargs": {},
},
}
def compute(
inputs: dict = {"design": {}, "implicit": {}, "setup": {}},
outputs: dict = {"design": {}, "implicit": {}, "setup": {}},
partials: dict = {},
options: dict = {},
parameters: dict = {
"user_input_files": [],
"inputs_folder_path": "",
"outputs_folder_path": "",
},
) -> dict:
"""Editable compute function."""
print("OpenMDAO problem setup started.")
workflow = parameters["workflow"]
run_folder = Path(parameters["outputs_folder_path"])
all_connections = parameters.get("all_connections", [])
# 1) define the simulation components
prob = om.Problem(reports=OPENMDAO_REPORTS)
# add groups
groups = {}
if "Groups" in parameters:
for group in parameters["Groups"]:
name = reformat_compname(group["name"])
kwargs = group.get("kwargs", {})
groups[name] = prob.model.add_subsystem(
name,
om.Group(),
**kwargs,
)
if "solvers" in group:
for solver in group["solvers"]:
if solver["type"] == "nonlinear_solver":
groups[name].nonlinear_solver = OM_DEFAULTS["nonlinear_solver"][
"class"
](**OM_DEFAULTS["nonlinear_solver"]["kwargs"])
solver_obj = groups[name].nonlinear_solver
elif solver["type"] == "linear_solver":
groups[name].linear_solver = OM_DEFAULTS["linear_solver"][
"class"
](**OM_DEFAULTS["linear_solver"]["kwargs"])
solver_obj = groups[name].nonlinear_solver
else:
raise ValueError(
f"Solver of type {solver['type']} is not implemented."
)
if "options" in solver:
for option, val in solver["options"].items():
if option in ["iprint", "maxiter"]:
solver_obj.options[option] = int(val)
else:
solver_obj.options[option] = val
# add components
def get_comp_by_name(name, objs: dict):
comp_type_lookup = {
"ExplicitComponents": OMexplicitComp,
"ImplicitComponents": OMimplicitComp,
}
for key, obj in objs.items():
filtered = [comp_obj for comp_obj in obj if comp_obj["name"] == name]
if filtered:
return [comp_type_lookup[key], filtered[0]]
return OMexplicitComp, None # default
model_lookup = {}
for component in workflow:
# defaults
kwargs = {}
fd_step = 0.1
model = prob.model
has_compute_partials = True # set this to False if fd gradients should be used
objs = {
k: parameters[k]
for k in ["ExplicitComponents", "ImplicitComponents"]
if k in parameters
}
comp_type, comp_obj = get_comp_by_name(component, objs)
if comp_obj:
kwargs = comp_obj.get("kwargs", kwargs)
fd_step = comp_obj.get("fd_step", fd_step)
has_compute_partials = comp_obj.get(
"has_compute_partials", has_compute_partials
)
model = groups.get(comp_obj.get("group"), model)
model_lookup[component] = model
model.add_subsystem(
reformat_compname(component),
comp_type(
compname=component,
fd_step=fd_step,
has_compute_partials=has_compute_partials,
),
**kwargs,
)
if "ExecComps" in parameters and parameters["ExecComps"]:
for component in parameters["ExecComps"]:
prob.model.add_subsystem(
reformat_compname(component["name"]),
om.ExecComp(component["exprs"]),
**component["kwargs"],
)
# 2) define the component connections
def get_var_str(c, name):
return f"{reformat_compname(c)}.{name.replace('.','-')}"
for connection in all_connections:
if connection["type"] == "design":
prob.model.connect(
get_var_str(connection["origin"], connection["name_origin"]),
get_var_str(connection["target"], connection["name_target"]),
)
if parameters["driver"]["type"] == "optimisation":
# 3) setup the optimisation driver options
prob.driver = om.ScipyOptimizeDriver()
prob.driver.options["optimizer"] = parameters["optimizer"]
prob.driver.options["maxiter"] = parameters["max_iter"]
prob.driver.options["tol"] = parameters["tol"]
prob.driver.opt_settings["disp"] = parameters["disp"]
prob.driver.options["debug_print"] = parameters["debug_print"]
if "approx_totals" in parameters and parameters["approx_totals"]:
# ensure FD gradients are used
prob.model.approx_totals(
method="fd", step=parameters["fd_step"], form=None, step_calc=None
)
elif parameters["driver"]["type"] == "doe":
# 3) alternative: setup a design of experiments
levels = parameters["driver"]["kwargs"].get("levels", 2)
if isinstance(levels, float): # All have the same number of levels
levels = int(levels)
elif isinstance(levels, dict): # Different DVs have different number of levels
levels = {k: int(v) for k, v in levels.items()}
prob.driver = DOEDriver(
om.FullFactorialGenerator(levels=levels),
reset_vars=parameters["driver"]["kwargs"].get("reset_vars", {}),
store_case_data=parameters["driver"]["kwargs"].get("store_case_data", {}),
store_parameters=parameters["driver"]["kwargs"].get("store_parameters", {}),
run_folder=run_folder,
)
# 4) add design variables
if "input_variables" in parameters:
for var in parameters["input_variables"]:
upper = var["upper"]
lower = var["lower"]
if "component" in var:
comp_obj = reformat_compname(var["component"])
prob.model.add_design_var(
f"{comp_obj}.{var['name'].replace('.', '-')}",
lower=lower,
upper=upper,
)
else:
prob.model.add_design_var(
var["name"].replace(".", "-"), lower=lower, upper=upper
)
val_default = var.get("value", lower)
prob.model.set_input_defaults(
var["name"].replace(".", "-"), val_default
)
# 5) add an objective and constraints
if "output_variables" in parameters:
for var in parameters["output_variables"]:
comp_obj = reformat_compname(var["component"])
name = f"{comp_obj}.{var['name'].replace('.', '-')}"
# set scaling from parameter input file
scaler = var.get("scaler", None)
adder = var.get("adder", None)
if var["type"] == "objective":
prob.model.add_objective(name, scaler=scaler, adder=adder)
elif var["type"] == "constraint":
lower = var.get("lower", None)
upper = var.get("upper", None)
prob.model.add_constraint(
name, lower=lower, upper=upper, scaler=scaler, adder=adder
)
prob.setup() # required to generate the n2 diagram
print("OpenMDAO problem setup completed.")
if "visualise" in parameters and "n2_diagram" in parameters["visualise"]:
# save n2 diagram in html format
om.n2(
prob,
outfile=str(run_folder / "n2.html"),
show_browser=False,
)
if parameters["driver"]["type"] == "optimisation":
dict_out = run_optimisation(prob, parameters, run_folder)
# elif parameters["driver"]["type"] == "check_partials":
# dict_out = run_check_partials(prob, parameters)
# elif parameters["driver"]["type"] == "check_totals":
# dict_out = run_check_totals(prob, parameters)
elif parameters["driver"]["type"] == "doe":
nb_threads = int(parameters["driver"].get("nb_threads", 1))
dict_out = run_doe(prob, parameters, run_folder, nb_threads=nb_threads)
# elif parameters["driver"]["type"] == "post":
# dict_out = run_post(prob, parameters)
else:
with open(run_folder / "trim_convergence.log", "w") as f:
with redirect_stdout(f):
prob.run_model()
dict_out = {}
message = f"{datetime.now().strftime('%Y%m%d-%H%M%S')}: OpenMDAO compute completed."
print(message)
if dict_out:
outputs["design"] = dict_out
return {"message": message, "outputs": outputs}
def run_optimisation(prob, parameters, run_folder):
# 6) add a data recorder to the optimisation problem
r_name = str(
run_folder
/ (
"om_problem_recorder_"
+ datetime.now().strftime("%Y%m%d-%H%M%S")
+ ".sqlite"
)
)
r = om.SqliteRecorder(r_name)
prob.driver.add_recorder(r)
prob.driver.recording_options["record_derivatives"] = True
# setup the problem again
prob.setup()
if "visualise" in parameters and "scaling_report" in parameters["visualise"]:
# NOTE: running the model can generate large large amounts of stored data in orchestrator, which
# can cause prob.setup() to fail if it is called again, so only execute
# prob.run_model() after all setup has been completed
try:
with open(run_folder / "scaling_report.log", "w") as f:
with redirect_stdout(f):
prob.run_model()
prob.driver.scaling_report(
outfile=str(run_folder / "driver_scaling_report.html"),
title=None,
show_browser=False,
jac=True,
)
except Exception as e:
with open(run_folder / "run_driver.log", "w") as f:
with redirect_stdout(f):
tb = traceback.format_exc()
print(f"OpenMDAO prob.run_model() exited with error: {e}")
print(tb)
raise ValueError(
"OpenMDAO prob.run_model() error. Check outputs/run_driver.log for details."
)
# 7) execute the optimisation
try:
with open(run_folder / "run_driver.log", "w") as f:
with redirect_stdout(f):
prob.run_driver()
except Exception as e:
with open(run_folder / "run_driver.log", "w") as f:
with redirect_stdout(f):
tb = traceback.format_exc()
print(f"run driver exited with error: {e}")
print(tb)
raise ValueError(
"OpenMDAO Optimisation error. Check outputs/run_driver.log for details."
)
opt_output = {}
# print("Completed model optimisation - solution is: \n inputs= (")
for var in parameters["input_variables"]:
name = var["name"]
# print(
# f"{comp}.{name}: "
# + str(prob.get_val(f"{comp}.{name.replace('.', '-')}"))
# + " "
# )
if "component" in var:
comp = var["component"]
opt_output[f"{comp}.{name}"] = prob.get_val(
f"{reformat_compname(comp)}.{name.replace('.', '-')}"
).tolist()
else:
opt_output[name] = prob.get_val(name.replace(".", "-")).tolist()
# print("), \n outputs = (")
for var in parameters["output_variables"]:
comp = var["component"]
name = var["name"]
# print(
# f"{comp}.{name}: "
# + str(prob.get_val(f"{comp}.{name.replace('.', '-')}"))
# + " "
# )
opt_output[f"{comp}.{name}"] = prob.get_val(
f"{reformat_compname(comp)}.{name.replace('.', '-')}"
).tolist()
# print(")")
print(opt_output)
if "visualise" in parameters and "plot_history" in parameters["visualise"]:
post_process_optimisation(parameters, run_folder, r_name)
return opt_output
def run_doe(prob, parameters, run_folder, nb_threads=1):
# 7) execute the driver in parallel
def run_cases_thread(color):
print(f"Starting thread {color}.")
prob_copy = deepcopy(prob)
print(f"problem id for color {color}: ", id(prob_copy))
# set driver instance properties
prob_copy.driver.nb_threads = nb_threads
prob_copy.driver.color = color
try:
prob_copy.run_driver()
except Exception as e:
print(f"run driver exited with error: {e}")
tb = traceback.format_exc()
return f"OpenMDAO DOE error: {tb}"
print(f"Completed thread {color}.")
with open(run_folder / f"run_driver.log", "w") as f:
with redirect_stdout(f):
with ThreadPoolExecutor(max_workers=nb_threads) as executor:
msgs = executor.map(run_cases_thread, range(nb_threads))
errors = list(msgs)
if errors and errors[0]:
raise ValueError(errors[0])
print("completed all threads")
if "visualise" in parameters and "plot_history" in parameters["visualise"]:
from post import post_process_doe
post_process_doe(
parameters,
run_folder,
files=[f"results_{c}.json" for c in range(nb_threads)],
)
return {}
def reformat_compname(name):
# openmdao doesn't allow "-" character in component names
return name.replace("-", "_")
def post_process_optimisation(
parameters, run_folder, r_name, only_plot_major_iter=True
):
# read database
# Instantiate your CaseReader
cr = om.CaseReader(r_name)
# Isolate "problem" as your source
driver_cases = cr.list_cases("driver", out_stream=None)
# plot the iteration history from the recorder data
inputs_history = {
key: []
for key in [
f"{reformat_compname(var['component'])}.{var['name'].replace('.', '-')}"
for var in parameters["input_variables"]
]
}
outputs_history = {
key: []
for key in [
f"{reformat_compname(var['component'])}.{var['name'].replace('.', '-')}"
for var in parameters["output_variables"]
]
}
for key in driver_cases:
case = cr.get_case(key)
if (only_plot_major_iter and case.derivatives) or not only_plot_major_iter:
# get history of inputs
for key in inputs_history:
inputs_history[key].append(case.outputs[key])
# get history of outputs
for key in outputs_history:
outputs_history[key].append(case.outputs[key])
# plot output in userfriendly fashion
_plot_iteration_histories(
inputs_history=inputs_history,
outputs_history=outputs_history,
run_folder=run_folder,
)
def _plot_iteration_histories(
inputs_history=None, outputs_history=None, run_folder=None
):
# plot input histories
for key in inputs_history:
input_data = inputs_history[key]
input_data = np.array(input_data)
iterations = range(input_data.shape[0])
plt.figure()
for data_series in input_data.T:
plt.plot(iterations, data_series, "-o")
plt.grid(True)
plt.title(key)
plt.savefig(str(run_folder / (key + ".png")))
# plot output histories
for key in outputs_history:
output_data = outputs_history[key]
output_data = np.array(output_data)
iterations = range(output_data.shape[0])
plt.figure()
for data_series in output_data.T:
plt.plot(iterations, data_series, "-o")
plt.grid(True)
plt.title(key)
plt.savefig(str(run_folder / (key + ".png")))
plt.show()
class DOEDriver(om.DOEDriver):
def __init__(
self,
generator=None,
reset_vars: dict = None,
store_case_data: list = None,
store_parameters: dict = None,
run_folder: Path = None,
**kwargs,
):
self.reset_vars = reset_vars
self.cases_store = []
self.store_case_data = store_case_data
self.store_parameters = store_parameters
self.run_folder = run_folder
self.nb_threads = 1
self.color = 0
super().__init__(generator=generator, **kwargs)
def run(self):
"""
Generate cases and run the model for each set of generated input values.
Returns
-------
bool
Failure flag; True if failed to converge, False is successful.
"""
self.iter_count = 0
self._quantities = []
# set driver name with current generator
self._set_name()
# Add all design variables
dv_meta = self._designvars
self._indep_list = list(dv_meta)
# Add all objectives
objs = self.get_objective_values()
for name in objs:
self._quantities.append(name)
# Add all constraints
con_meta = self._cons
for name, _ in con_meta.items():
self._quantities.append(name)
for case in self._parallel_generator(self._designvars, self._problem().model):
print(f"Starting case on thread {self.color}.")
self._custom_reset_variables()
self._run_case(case)
self.iter_count += 1
self._custom_store_to_json()
return False
def _custom_reset_variables(self):
# reset the initial variable guesses
for k, v in self.reset_vars.items():
self._problem()[k] = v
def _custom_store_to_json(self):
# store the outputs to the json database
self.cases_store.append(
{
**self.store_parameters,
**{
k.split(".")[-1]: self._problem()[k][0]
for k in self.store_case_data
},
}
)
# dump to json file
fname = f"results_{self.color}.json"
with open(self.run_folder / fname, "w", encoding="utf-8") as f:
json.dump(self.cases_store, f)
def _parallel_generator(self, design_vars, model=None):
"""
Generate case for this thread.
Parameters
----------
design_vars : dict
Dictionary of design variables for which to generate values.
model : Group
The model containing the design variables (used by some generators).
Yields
------
list
list of name, value tuples for the design variables.
"""
size = self.nb_threads
color = self.color
generator = self.options["generator"]
for i, case in enumerate(generator(design_vars, model)):
if i % size == color:
yield case
if __name__ == "__main__":
with open("open-mdao-driver/parameters.json", "r") as f:
parameters = json.load(f)
parameters["all_connections"] = [
{
"origin": "vspaero",
"name_origin": "CL",
"target": "trim",
"name_target": "CL",
"type": "design",
},
{
"origin": "vspaero",
"name_origin": "CMy",
"target": "trim",
"name_target": "CMy",
"type": "design",
},
]
parameters["workflow"] = ["vspaero", "trim"] # defined by controller
parameters["outputs_folder_path"] = "outputs" # defined by component generic api
compute(
inputs={},
outputs={"design": {}},
partials=None,
options=None,
parameters=parameters,
)
numpy==1.23.5
openmdao==3.28.0
matplotlib==3.7.0
fluids==1.0.22
pandas==1.5.3
{
"user_input_files": [],
"optimizer": "SLSQP",
"max_iter": 20,
"tol": 1e-8,
"disp": true,
"debug_print": [
"desvars",
"ln_cons",
"nl_cons",
"objs",
"totals"
],
"approx_totals": true,
"fd_step": 0.0001,
"input_variables": [
{
"component": "paraboloid",
"name": "x",
"lower": -50,
"upper": 50
},
{
"component": "paraboloid",
"name": "y",
"lower": -50,
"upper": 50
}
],
"output_variables": [
{
"component": "paraboloid",
"type": "objective",
"name": "f_xy"
}
],
"driver": {
"type": "optimisation"
},
"visualise": [
"n2_diagram",
"plot_history"
]
}
""" Optimisation Component classes for OpenMDAO and associated utilities."""
import numpy as np
import openmdao.api as om # type: ignore
from component_api2 import call_compute, call_setup
import traceback
class OMexplicitComp(om.ExplicitComponent):
"""standard component that follows the OM conventions"""
def __init__(self, compname, fd_step, has_compute_partials=True):
super().__init__()
self.compname = compname
self.get_grads = False
self.iter = 0
self.partial_dict = None
self.fd_step = fd_step
self._has_compute_partials = has_compute_partials # overrides parent class attribute with user defined parameter
def setup(self):
message = {"component": self.compname}
_, component_dict = call_setup(message)
inputs = component_dict["input_data"]["design"]
outputs = component_dict["output_data"]["design"]
# initialise the inputs
if inputs:
for variable in inputs:
self.add_input(variable.replace(".", "-"), val=inputs[variable])
# initialise the outputs
if outputs:
for variable in outputs:
self.add_output(variable.replace(".", "-"), val=outputs[variable])
def setup_partials(self):
# Get the component partial derivative information
message = {"component": self.compname}
_, component_dict = call_setup(message)
if "partials" in component_dict and component_dict["partials"]:
self.partial_dict = component_dict["partials"]
for resp, vars in self.partial_dict.items():
for var, vals in vars.items():
self.declare_partials(
resp.replace(".", "-"), var.replace(".", "-"), **vals
)
else:
# calculate all paritials using finite differencing
self.declare_partials("*", "*", method="fd", step=self.fd_step)
def compute(self, inputs, outputs, discrete_inputs=None, discrete_outputs=None):
print("Calling compute.")
# calculate the outputs
# Note: transform all np.ndarrays into nested lists to allow formatting to json
input_dict = {"design": reformat_inputs(inputs._copy_views())}
message = {
"component": self.compname,
"inputs": input_dict,
"get_grads": False,
"get_outputs": True,
}
print("message: \n", str(message))
try:
_, data = call_compute(message)
if not "outputs" in data:
raise ValueError(f"Error: Compute output missing - output was: {data}.")
except Exception as e:
print(f"Compute of {self.compname} failed, input data was: {str(message)}")
tb = traceback.format_exc()
print(tb)
raise ValueError(
f"OM Explicit component {self.compname} compute error: " + tb
)
val_outputs = data["outputs"]["design"]
# OpenMDAO doesn't like the outputs dictionary to be overwritten, so
# assign individual outputs one at a time instead
for output in outputs:
outputs[output] = val_outputs[output.replace("-", ".")]
def compute_partials(self, inputs, J):
"""Jacobian of partial derivatives."""
print("Calling compute_partials.")
self.iter += 1
input_dict = reformat_inputs(inputs._copy_views())
message = {
"component": self.compname,
"inputs": input_dict,
"get_grads": True,
"get_outputs": False,
}
print("message: \n", str(message))
try:
_, data = call_compute(message)
if not "partials" in data:
raise ValueError(
f"Error: Compute partial derivatives missing - output was: {data}."
)
self.partial_dict = data["partials"]
except Exception as e:
print(
f"Compute partials of {self.compname} failed, input data was: {str(message)}"
)
tb = traceback.format_exc()
print(tb)
raise ValueError(
f"OM Explicit component {self.compname} compute error: " + tb
)
if self.partial_dict:
for resp, vars in self.partial_dict.items():
for var, vals in vars.items():
if "val" in vals:
J[resp.replace(".", "-"), var.replace(".", "-")] = vals["val"]
# print(dict(J))
else:
raise ValueError(f"Component {self.compname} has no Jacobian defined.")
class OMimplicitComp(om.ImplicitComponent):
"""standard implicit component that follows the OM conventions"""
def __init__(self, compname, fd_step, has_compute_partials=False):
super().__init__()
self.compname = compname
self.get_grads = False
self.iter = 0
self.partial_dict = None
self.fd_step = fd_step
def setup(self):
message = {"component": self.compname}
_, component_dict = call_setup(message)
inputs = component_dict["input_data"]["design"]
outputs = component_dict["output_data"]["design"]
# initialise the inputs
if inputs:
for variable in inputs:
self.add_input(variable.replace(".", "-"), val=inputs[variable])
# initialise the outputs
if outputs:
for variable in outputs:
self.add_output(variable.replace(".", "-"), val=outputs[variable])
def setup_partials(self):
message = {"component": self.compname}
_, component_dict = call_setup(message)
if "partials" in component_dict and component_dict["partials"]:
self.partial_dict = component_dict["partials"]
for resp, vars in self.partial_dict.items():
for var, vals in vars.items():
self.declare_partials(
resp.replace(".", "-"), var.replace(".", "-"), **vals
)
else:
# calculate all paritials using finite differencing
self.declare_partials("*", "*", method="fd", step=self.fd_step)
def apply_nonlinear(self, inputs, outputs, residuals):
input_dict = {"design": reformat_inputs(inputs._copy_views())}
message = {
"component": self.compname,
"inputs": input_dict,
"get_grads": False,
"get_outputs": True,
}
print("message: \n", str(message))
try:
_, data = call_compute(message)
if not "outputs" in data:
raise ValueError(f"Error: Compute output missing - output was: {data}.")
except Exception as e:
print(f"Compute of {self.compname} failed, input data was: {str(message)}")
tb = traceback.format_exc()
print(tb)
raise ValueError(
f"OM Explicit component {self.compname} compute error: " + tb
)
val_outputs = data["outputs"]["design"]
for output in outputs:
residuals[output] = val_outputs[output.replace("-", ".")]
def reformat_inputs(inputs):
input_dict = inputs
for key in [*input_dict.keys()]:
new_key = key.split(".")[-1].replace("-", ".")
input_dict[new_key] = input_dict.pop(key)
if isinstance(input_dict[new_key], np.ndarray):
input_dict[new_key] = input_dict[new_key].tolist()
return input_dict
6.4.1. Execute the workflow#
We can now execute the design optimisation by selecting the play symbol ▶ in the Run controls interface.
As before, the Run should complete after 13 iterations of the paraboloid component (1 iteration of the open-mdao component).
6.4.2. Inspect the outputs#
The Run log summarises the output of the components. Open the log by selecting View Log in the interface controls.
The “run_output” entry (at the end of the log) should state that the “OpenMDAO compute completed”.
Next, close the Run log and select the paraboloid component.
Then select the Log tab and click on download files snapshot.
Open the downloaded zip folder and open the ‘paraboloid.ods’ output spreadsheet under the outputs folder. The optimisation history data should appear as iterations 0 to 12 to the left of the sheet. This data should also be plotted in the line-plots to the right. The history data includes major iterations, minor iterations (line searches) and function evaluations used to calculate the finite difference gradients used by the SLSQP algorithm.
Similarly, you can inspect the outputs of the open-mdao component, which should include convergence history plots, showing the major iterations only.
Finally, you can save the session data and Run log by selecting Download from the interface controls.
6.5. Clean-up#
Delete your session by selecting New in the interface.
It may take a minute or so for the Cloud session to be reset.